Vision
ActionStep Reference » OpenAI » Image » Vision
The OpenAI Vision ActionStep provides an advanced image analysis solution by leveraging OpenAI's AI models. This tool can interpret and provide insights on visual data based on user-provided instructions. For example, the AI describes the following image as follows:

Response of the AI:
"This image shows a close-up of a multi-pin electrical connector with a bundle of wires coming from it. The connectors are colored (red and green casings with red electronics inside), and they look like they might be part of a vehicle's electrical system, a complex piece of machinery, or a computer system. These connectors are used to join different parts of an electrical circuit and often allow for quick disconnection and reconnection. The array of colorful insulated wires suggests that the system they belong to carries various signals and power feeds, with each wire having a specific function within the apparatus."
- Open the OpenAI node in the Workspace Explorer.
- In the Image node, select the Vision ActionStep.
Parameters:
The ActionStep has the following input parameters:
| Name |
Description
|
|---|---|
| API Key | The OpenAI API key. Allowed Context Scopes [Fixed, Local, Global, Reference] Allowed Context Types [Fixed, Variable, Parameter, Result, Enum] Allowed Context Values [String] |
| Image | The target image. Allowed Context Scopes [Fixed, Local, Global, Reference] Allowed Context Types [Fixed, Variable, Parameter, Result, Enum] Allowed Context Values [String] |
| Prompt | Specific instructions or questions about the image to guide the analysis. Allowed Context Scopes [Fixed, Local, Global, Reference] Allowed Context Types [Fixed, Variable, Parameter, Result, Enum] Allowed Context Values [String] |
| JSON Template | An optional parameter defining the structure of the JSON output for consistent data extraction. Allowed Context Scopes [Fixed, Local, Global, Reference] Allowed Context Types [Fixed, Variable, Parameter, Result, Enum] Allowed Context Values [String] |
| Timeout | The time in milliseconds that the ActionStep will wait for the API to respond before considering the request timed out. Allowed Context Scopes [Fixed, Local, Global, Reference] Allowed Context Types [Fixed, Variable, Parameter, Result, Enum] Allowed Context Values [Int64] |
Results:
The ActionStep returns the following results:
| name |
Description
|
|---|---|
| Success | Indicates whether the result is successful. Allowed Context Scopes [Fixed, Local, Global, Reference] Allowed Context Types [Fixed, Variable, Parameter, Result, Enum] Allowed Context Values [Boolean] |
| JSON Output | The extracted data in JSON format detailing the important aspects of the image. Allowed Context Scopes [Fixed, Local, Global, Reference] Allowed Context Types [Fixed, Variable, Parameter, Result, Enum] Allowed Context Values [String] |
| Number Of Lines | The number of sentences in the response data. Allowed Context Scopes [Fixed, Local, Global, Reference] Allowed Context Types [Fixed, Variable, Parameter, Result, Enum] Allowed Context Values [Int64] |
| Lines | The output text lines. Allowed Context Scopes [Fixed] Allowed Context Types [Fixed] |
Example 1 (Analyze image and output result):
This ActionScript example demonstrates an image analysis process using the OpenAI Vision ActionStep. It begins by submitting an image along with a prompt asking what can be seen in the image to OpenAI's API. Upon successful analysis, the API returns a JSON output containing detailed descriptions, which is then checked for validity. If the JSON output is not empty, the script parses this output to extract specific details about the image, such as the subject, system parts, purpose, and typical applications of the item in the image. Finally, if the JSON contains valid information, the script converts this textual information into speech using the OpenAI Text To Speech ActionStep, creating an audio representation of the image's content.
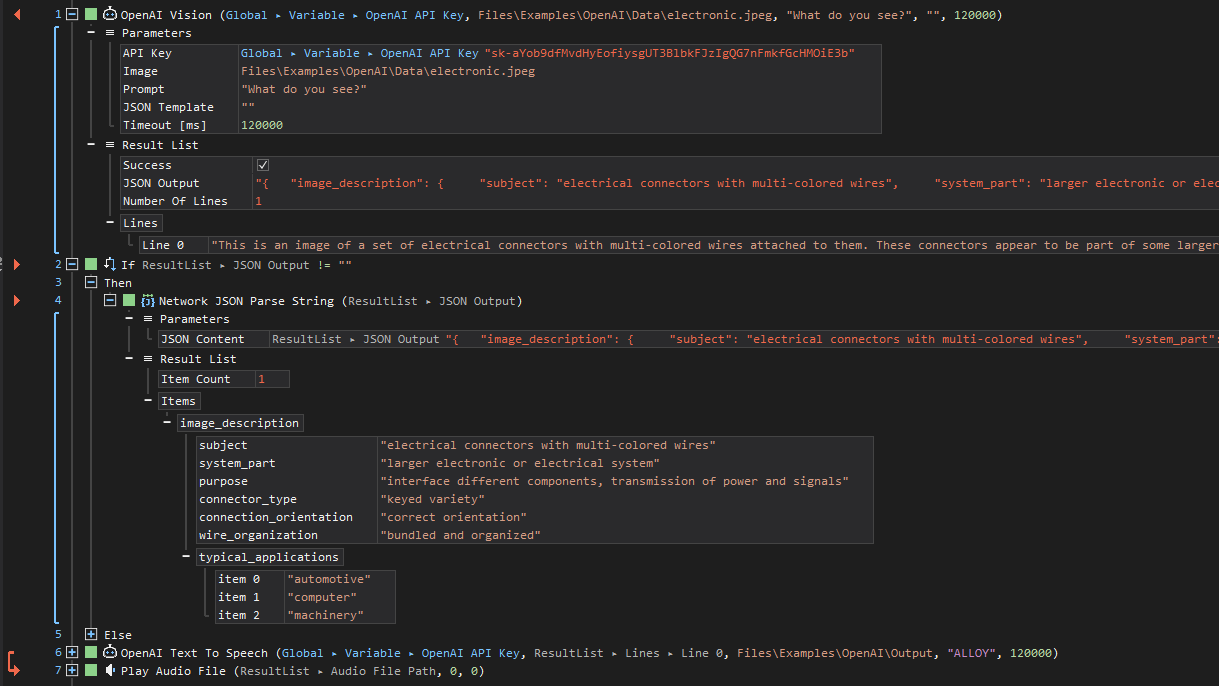
See other operations: